

Data is a necessary factor in decision-making. And, without web scraping, acquiring it becomes much more challenging in today’s digital era. Wondering what’s web scraping? Well, Python web scraping helps companies collect huge amounts of data from websites for competitor analysis, understanding market trends, and overall data-driven strategy. Python also offers a wide range of libraries that make extracting and utilizing data from websites feasible, providing businesses with a valuable advantage.
Given today's data explosion, businesses worldwide need to stay ahead by rapidly tapping into huge volumes of online information every day. And by using web scraping, companies can make it possible in an efficient and scalable manner. That’s why it is now more of a necessity for businesses seeking a competitive edge.
Many popular names from the industry hire Python developers just to take advantage of web scraping for their profits. For instance-
-
Amazon uses web scraping to trace competitor prices so that they can regulate their pricing strategy every minute of the day.
-
Zillow, a famous American tech real-estate marketplace uses web scraping to compile listings of real estate properties and thereby offer available trend data on the U.S. housing market.
-
LinkedIn, every ‘professional go-to social media’ also uses web scraping to maintain the most up-to-date information on job vacancies and further connections.
With these examples, it's quite obvious how important web scraping is for companies to compete and take data-driven action.
Quick Summary:
This blog takes you through an overview of web scraping, how to extract data with Python’s web scraping and its advantages for IT companies along with a detailed list of 7 best Python libraries you can utilize for web scraping, including Beautiful Soup, Scrapy, Selenium & more with their features, advantages, and disadvantages.
Let’s start with the definition then!
Overview: Web scraping
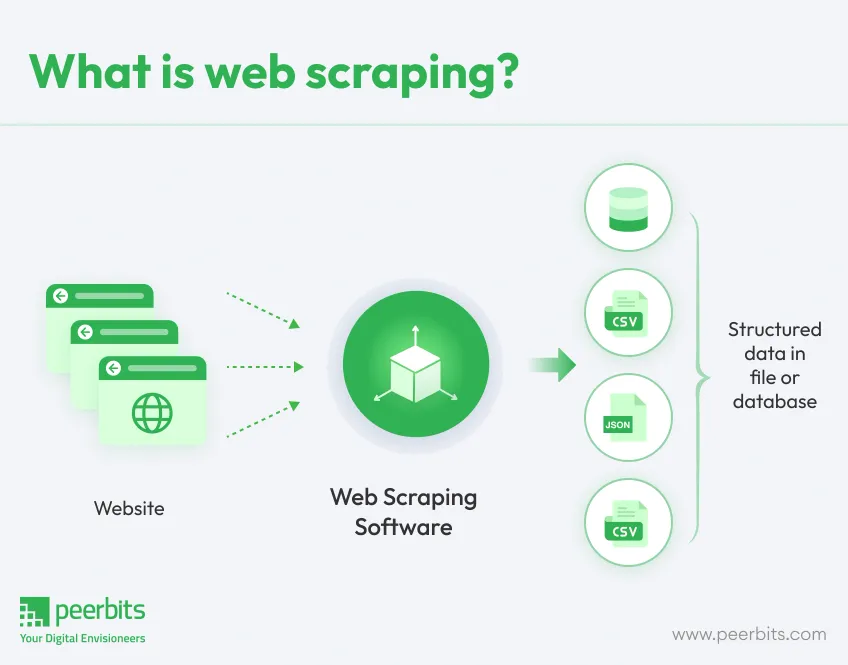
Web scraping is a modern technique that is used to automatically collect a bulk amount of data from websites, transforming web-based unstructured information into structured data for more in-depth analysis. It does this by sending HTTP requests to the server that hosts a website, fetching HTML elements of the web, and then parsing (analyzing a document's structure to extract specific data) those HTML elements in order to scrap desired information.
Web Scraping is not just limited to fetching data. It has a variety of use cases across different industries, from market research & price monitoring to lead generation or sentiment analysis. To keep your scraping process effective and legal, you should be aware of the right tools and best practices for web scraping.
Python's extensive library collection has made this extensive task of web scraping much easier. Let’s see how IT companies can benefit from this revolutionary Python technique.
How do IT companies benefit from web scraping?
It's evident from the above examples, that web scraping is an inevitable technology for any company trying to stay ahead of the competition. Here are some ways in which IT companies can take advantage of web scraping:
-
Competitive Analysis: Check & analyze the price and customer feedback from your competitors through the collected data.
-
Data Intelligence: Use data to find new business opportunities and save them for lead generation.
-
Market Research: Study of trends and customer preferences.
-
Content Curation: Automate and also gather relevant content.
-
Ingest Data: Bringing in more detailed online information to enrich the datasets
-
SEO monitoring: Monitor competitor's keywords and content.
-
Advance Sentiment Prediction: Predict the sentiment from reviews & social media
These benefits of web scraping prove its effectiveness in helping both large & small companies to better their game, make well-founded decisions, and know when to upscale by understanding the market.
How to extract data with Python’s web scraping?
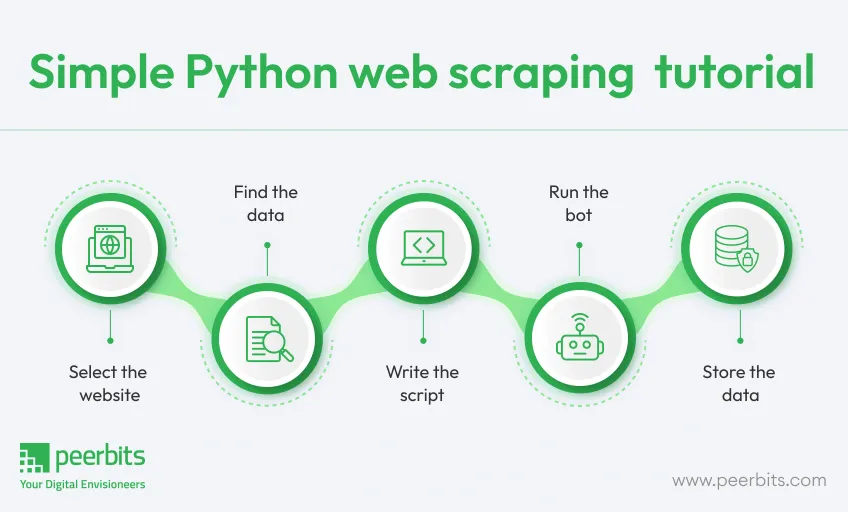
For scraping data, there are several web scraping libraries you can use with Python (We just need to choose the library based on task complexity). Beautiful Soup is the best library for static web pages. It is just too good to parse/append HTML (can do XML as well) documents and query the elements in a document tree.
To get started with this Python web scraping tutorial:
-
You have to use the Request library to scrape the HTML content of a web page.
-
Then, you can use Beautiful Soup to parse this content and extract things like text, links, or images easily. For scraping tasks that involve no need for dynamic page changes, this combination is perfect.
For example, when simple scraping operations with straightforward web formats are required (such as static pages) other libraries like Selenium or Scrapy can provide further advanced functionalities to cope with dynamic content rendered by JavaScript. Browser automation is covered by Selenium, functioning as a puppeteer to issue browser commands that would include clicking buttons and submitting forms like you are doing in the scraping data, it allows Python Developers to automate landing page journey scenarios.
However, it is especially useful to scrape screens from websites that need you to first log in or have some interaction with the website. Scrapy: A full-fledged web scraping framework for large-scale projects. This is used to manage requests, navigate through multiple pages, and work with huge amounts of data sets.

Best Python libraries for web scraping
Now you’ve got the idea of Python’s web scraping awesomeness! Let’s take a look at some of the leading Python libraries and their respective features. Whether you are a beginner or looking to hire Python web developers it will help you easily collect and manage data from the web:

1. Beautiful Soup: Simple yet powerful
For some organizations who are just getting into web scraping, Beautiful Soup is the go-to choice. A Python library that provides super easy options to extract specific information from HTML and XML documents. It is suited to small projects or scraping static sites.
Beautiful Soup has been used by companies like Intuit and Airbnb to perform basic scraping of websites.
Features:
-
Helps in parsing HTML and XML documents to create a parse tree.
-
This enables more ease of navigation and search within the document.
-
Great for small projects and basic scraping.
Advantages:
-
Easy to learn and apply for newcomers.
-
Low setup—install the library and you are good to run.
-
Good for scraping web pages that are simple and static with minimal interaction.
Disadvantages:
-
Large-scale scraping or dynamic content Scraping.
-
Slowest when it comes to more complex scraping tasks.
2. Scrapy: The complete web scraping framework
Scrapy is a great choice for businesses that want to scale their web scraping program. This is a Python framework that provides all the tools needed to build spiders (or you can say crawlers) for navigating the web and extracting large amounts of data quickly.
Software companies like Lyst and DataCamp rely on Scrapy to construct high-powered web crawlers or spiders that collect massive data sets for analysis.
Features:
-
Built-in support for request handling cookies, and link following.
-
Offers a powerful scraping environment with options for data storage and export.
-
Asynchronous requests for faster scraping in greater value.
Advantages:
-
Highly performant and speedy due to its nature of asynchronous working.
-
Great for larger projects with many items to scrape
-
Highly configurable with middleware, extensions, and settings for expanded functionality
Disadvantages:
-
Those inexperienced with web scraping face a steeper learning curve.
-
More code to set up than there would be with a library like Beautiful Soup.
3. Selenium: Great for dynamic websites
Selenium is a great web scraping library but more than that it is a browser automation tool. Great for crawling dynamic JavaScript-heavy websites where you might have to interact with the page.
Companies like Google and Shopify use Selenium to automate testing, it is also a popular choice for scraping dynamic content.
Features:
-
It works with almost every browser (be it Chrome, Firefox, Safari, etc.)
-
Facilitates web actions like button clicks and form fills by automating a headless browser.
-
Good for scraping sites with dynamic content requiring Javascript rendering.
Advantages:
-
Can work with web pages containing a massive amount of JavaScript.
-
Provides full browser automation (not just scraping).
-
It is adaptable for versatility to various scraping requirements or simulating user actions.
Disadvantages:
-
Not as performant as static content compared to other scraping libraries
-
Needs a browser driver and more fiddling.
4. Requests: HTTP for humans
Requests is a popular and lightweight HTTP library that is used for making requests in Python. Good for simple scraping, i.e. scraping of web pages where all you need to do is get the HTML page.
Reddit and Spotify are examples of some businesses using Requests to pull data for quick analysis.
Features:
-
Supports all HTTP Requests (GET, POST, PUT, DELETE etc)
-
This set of modules comes with the concept and also handles WebSockets, cookies, sessions, and redirects out-of-the-box.
-
It provides an API that is very simple and easy to use.
Advantages:
-
Great for simple, on-off data fetching tasks.
-
Python script interfaces are very easy to integrate and use.
-
Great for simple scraping tasks.
Disadvantages:
-
Does not have HTML parsing abilities, it just reads the HTML content.
-
Limited for modern scraping requirements, particularly around dynamic content.
Also read: Ultimate guide to Python frameworks for building scalable microservices
5. Urllib3: The advanced HTTP client
Urllib3 (best for developers needing more control over HTTP requests) It is the most powerful HTTP library in Python, with features such as connection pooling and retries.
Netflix uses Urllib3 to do low-level HTTP handling in their backend services.
Features:
-
Supports HTTPS, connection pooling, and retries.
-
Conforms to HTTP, allowing fine-grained control over requests and responses.
-
Supports secure hearts and an SSL certificate by default.
Advantages:
-
Provides more control and customization than requests
-
Suitable for use cases that need some overhead of connection management and retries.
-
For a backend service that needs full control over HTTP.
Disadvantages:
-
Far more Polyfill than Requests.
-
HTTP Layer: Recommended for advanced users who know more about HTTP protocols.
6. Lxml: The speed demon
If it comes to the parsing of big documents faster, Lxml is the best option. The speed is unreal and efficient as it is implemented on the C libraries.
Lxml is employed by LinkedIn and Bloomberg for high-performance web scraping, and data parsing jobs where speed matters most of the time.
Features:
-
Efficient XML and HTML parsing.
-
Advanced querying and transformation support (using XPATH & XSLT)
-
Integrated with Beautiful Soup for shortcuts to navigate/pull data.
Advantages:
-
Quick as a wink thanks to its framework
-
Optimal for large-scale scraping and data processing.
-
Supports XPath and XSLT-based complex queries
Disadvantages:
-
Requires familiarity with XML parsing
-
Best for more advanced stuff, overkill if you just want to scrape something in a stupid simple way.
7. MechanicalSoup: The lightweight browser
MechanicalSoup provides a kind of middle ground where you would like to do some browser automation but don't have enough time to get into Selenium. Works great for simple interactions such as form submission.
Mozilla and Dropbox have used MechanicalSoup for web-scraping or automated interactions.
Features:
-
Under the hood, it uses Beautiful Soup for parsing.
-
Provides methods to interact with forms, buttons, and other web elements
-
This is lightweight and faster than Selenium for basic operations.
Advantages:
-
Fewer dependencies than Selenium, and is very easy to set up.
-
Quick and good for small tasks that need interaction but not full-blown browser automation.
-
Power and simplicity in perfect balance.
Disadvantages:
-
The Selenium webdriver is better hands down for complex and Javascript-heavy pages.
-
Fewer resources, a smaller community, and documentation.
Conclusion
In summary, choosing a Python library for web scraping largely depends on your specific objectives and the complexity of the task. Beautiful Soup or Requests can handle simpler projects. For more complex use cases, especially with dynamic content, Scrapy or Selenium are better options. Moreover, MechanicalSoup offers a straightforward way to work with HTTP requests for simpler tasks.
These libraries are instrumental in shaping data acquisition strategies for many companies. To maximize the benefits of web scraping for your business, hire offshore Python developers who specialize in these tools. They can help you navigate the complexities of web scraping effectively. Just remember to always scrape responsibly and comply with the terms of service of the websites you target. In data-driven decision-making, the first step often isn't analysis but rather finding and scraping suitable datasets.

FAQ's
Web scraping is a Python technique that is used to extract large records from websites. This is the task of scraping a website by downloading HTML content and parsing it to get information for various purposes like data analysis, market research, or competitive intelligence.
- Obey the terms of service and robots.txt file provided for the website txt rules.
- Sending messages in chunks and with proper headers to avoid being throttled/block.
- Exceptions & errors handling.
- Make sure you are not crossing any legal or ethical boundaries.
- Rate limits those implementations, and consider using proxies for request distribution.
Python is an easy option for web scraping, thanks to its easy syntax and extensive libraries that any developer can utilize. Libraries such as Beautiful Soup, Scrapy, and Selenium allow users to easily navigate web pages under specifically desired content. Python’s flexibility and ease of use make it the most favored language for many extraction tasks.
No, NumPy is not used for web scraping. It’s for numerical computations and data manipulation. For scraping, use libraries like Beautiful Soup, Scrapy, or Selenium. However, NumPy can be useful after scraping if you need to perform numerical analysis or manipulate the data you've collected.









